Metidos como estamos en la revolución de la IA parece que siempre tenemos que usar proveedores en la nube. Aunque tiene sus ventajas como la facilidad para arrancar también tiene grandes inconvenientes como son el coste, la privacidad y nos limita las posibilidades de experimentación.
Existen muchas opciones de implantar modelos de lenguaje extensos LLM en local para poder usarlos tanto para experimentar como para tareas de producción.
En este artículo vamos a ver la forma más sencilla de desplegar Ollama y OpenWebUI para poder probar modelos de lenguaje en nuestra propia infraestructura.
Ollama es la aplicación que ejecuta los modelos mientras que OpenWebUI es una interfaz web similar a la que nos encontramos en modelos comerciales como ChatGPT.
Entre los modelos que nos permite ejecutar Ollama tendremos Llama 3.3, DeepSeek-R1, Phi-4, Gemma 3, Mistral Small 3.1entre otros.
Requisitos
En general todo lo relacionado con IA tiene unos requisitos de hardware bastante elevados. Al utilizar aplicaciones en la nube todo esto queda fuera de nuestra vista así que no le damos importancia pero en local pronto nos daremos cuenta de lo costoso que es términos computacionales.
En este artículo vamos a configurar Ollama para que únicamente utilice nuestra CPU. Este es el caso más sencillo pero también será una gran limitación porque los LLM están muy orientados a utilizar GPUs para funcionar. Podremos ejecutar algunos modelos sencillos pero todo irá lento y probablemente no podremos pasar de un entorno de testing.
El único requisito para una instalación básica será tener Docker instalado. En cuestión de memoria necesitaremos un mínimo de 16GB o mejor si hay más disponible. El tamaño en disco dependerá del modelo o modelos instalados pero a partir de 10GB puede ser una buena cantidad para empezar.
En otros artículos veremos las opciones que tenemos para hacer funcionar Ollama con GPUs tanto de Nvidia como de AMD para acelerar enormemente la capacidad de cálculo.
Despliegue
Como siempre tendremos varias opciones de despliegue pero en este caso únicamente necesitaremos una instalación de Docker reciente que incluya Docker compose. En mi caso Docker está en un contenedor en Proxmox pero para este despliegue no es importante, podría estar en una VM o incluso en nuestra máquina local.
Utilizaremos el siguiente fichero compose para desplegar y vincular las dos aplicaciones.
services:
ollama:
image: ollama/ollama
container_name: ollama
ports:
- "11434:11434"
volumes:
- ollama:/root/.ollama
restart: always
openwebui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
ports:
- "3006:8080"
environment:
- OLLAMA_BASE_URL=http://host.docker.internal:11434
extra_hosts:
- host.docker.internal:host-gateway
volumes:
- open-webui:/app/backend/data
restart: always
volumes:
ollama:
open-webui:Arrancaremos los contenedores con el comando habitual:
docker compose up -dEn unos minutos podremos acceder a la interfaz web en la URL que esté ejecutándose Docker en el puerto 3006.
Si todo ha funcionado nos aparecerá las imágenes de presentación de OpenWebUI:
Crearemos nuestro usuario de administración:

Y finalmente accederemos a la aplicación:
Todavía no podremos interactuar con ningún modelo de IA porque tendremos que cargarlos en Ollama. Para añadirlo haremos click en nuestro perfil de usuario en la parte superior derecha:

Después en settings y models:

Para cargar un modelo nos iremos al icono de manage models en la esquina superior derecha:

Para hacer nuestras primeras pruebas podemos descargar un modelo muy ligero como es llama3.2:1b. Escribiremos el nombre del modelo en el campo correspondiente, pulsaremos en descargar y cerraremos la ventana.
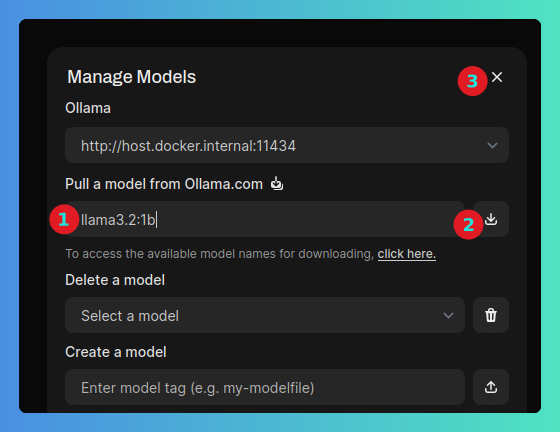
El modelo se descargará en segundo plano y estará disponible en unos segundos. Volveremos a la página principal y, cuando el modelo esté descargado aparecerá automáticamente en la parte superior.
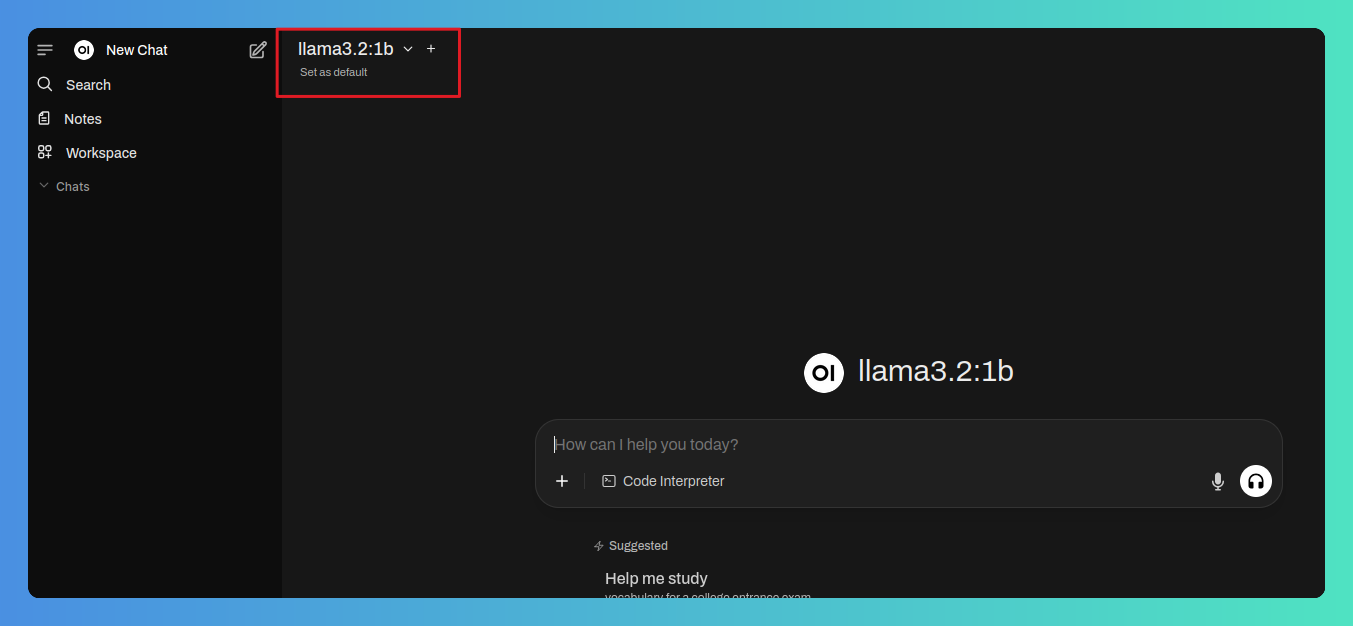
En este momento ya podremos interactuar con el modelo de la forma habitual:

Comentarios